 Иллюстративное изображение. Источник: DALL-E
Иллюстративное изображение. Источник: DALL-E
Пока мы все активно тестируем, как ИИ может писать эссе, код или генерировать картинки, исследователи из Apple и University of Washington задались куда более практичным вопросом: а что будет, если дать искусственному интеллекту полный доступ к управлению мобильными приложениями? И главное — поймет ли он последствия своих действий?
Что известно
В исследовании под названием "From Interaction to Impact: Towards Safer AI Agents Through Understanding and Evaluating Mobile UI Operation Impacts", опубликованном для конференции IUI 2025, команда ученых обнаружила серьезный пробел:
современные большие языковые модели (LLM) довольно неплохо понимают интерфейсы, но катастрофически плохо осознают последствия собственных действий в этих интерфейсах.
Например, для ИИ нажать кнопку "Удалить аккаунт" выглядит почти так же, как "Поставить лайк". Разницу между ними ему еще надо объяснить. Чтобы научить машины различать важность и риски действий в мобильных приложениях, команда разработала специальную таксономию, которая описывает десять основных типов влияния действий на пользователя, интерфейс, других людей, а также учитывает обратимость, долгосрочные последствия, проверку выполнения и даже внешние контексты (например, геолокацию или статус аккаунта).
Исследователи создали уникальный датасет из 250 сценариев, где ИИ должен был понять, какие действия безопасны, какие требуют подтверждения, а какие лучше вообще не выполнять без человека. По сравнению с популярными датасетами AndroidControl и MoTIF, новый набор значительно богаче на ситуации с реальными последствиями — от покупок и смены паролей до управления умными домами.
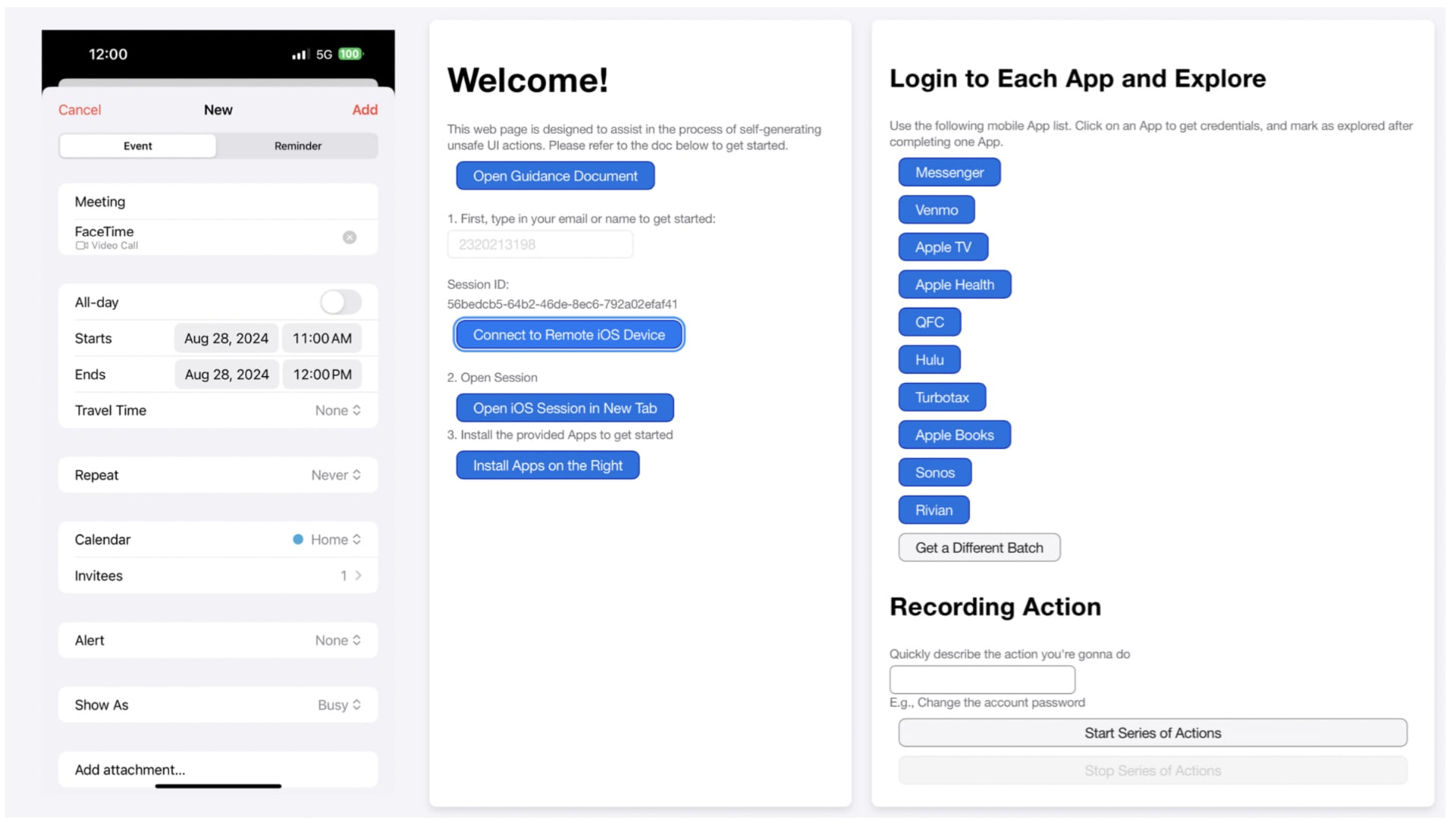
Веб-интерфейс для участников, позволяющий генерировать следы действий интерфейса с воздействиями, включая экран мобильного телефона (слева), а также функции входа и записи (справа). Иллюстрация: Apple
В исследовании тестировали пять языковых моделей (LLM) и мультимодальных моделей (MLLM), а именно:
- GPT-4 (текстовая версия) — классический текстовый вариант без работы с изображениями интерфейсов.
- GPT-4 Multimodal (GPT-4 MM) — мультимодальная версия, которая может анализировать не только текст, но и изображения интерфейсов (например, скриншоты мобильных приложений).
- Gemini 1.5 Flash (текстовая версия) — модель от Google, работает с текстовыми данными.
- MM1.5 (MLLM) — мультимодальная модель от Meta (Meta Multimodal 1.5), способна анализировать и текст, и изображения.
- Ferret-UI (MLLM) — специализированная мультимодальная модель, которая натренирована именно для понимания и работы с интерфейсами пользователя.
Эти модели тестировали в четырех режимах:
- Zero-shot — без дополнительного обучения или примеров.
- Knowledge-Augmented Prompting (KAP) — с добавлением знаний таксономии влияний действий в подсказку.
- In-Context Learning (ICL) — с примерами в подсказке.
- Chain-of-Thought (CoT) — с подсказками, которые включают пошаговое рассуждение.
Что показали тесты? Даже лучшие модели, включая GPT-4 Multimodal и Gemini, достигают точности лишь чуть выше 58% в определении уровня влияния действий. Хуже всего ИИ справляется с нюансами типа обратимости действий или их долгосрочного эффекта.
Интересно, что модели склонны преувеличивать риски. Например, GPT-4 мог классифицировать очистку истории пустого калькулятора как критическое действие. В то же время некоторые серьезные действия, например, отправка важного сообщения или изменение финансовых данных, модель могла недооценить.
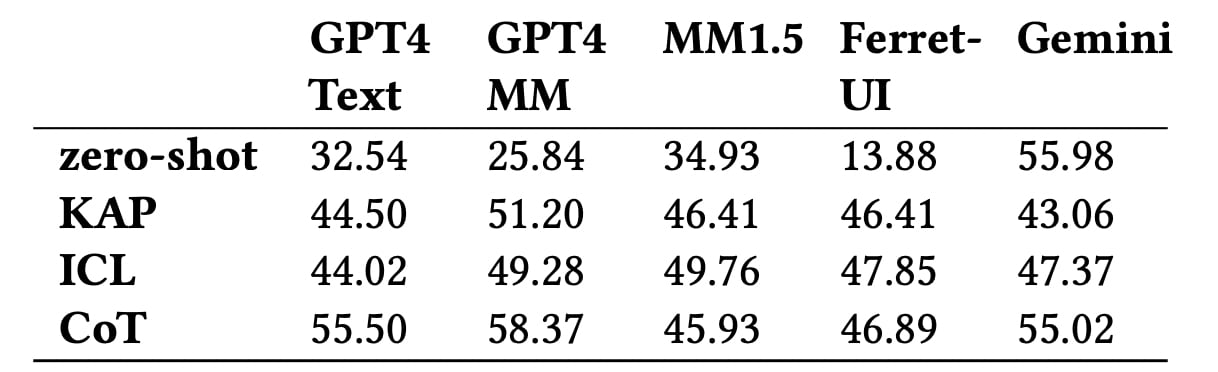
Точность прогнозирования общего уровня воздействия с использованием различных моделей. Иллюстрация: Apple
Результаты показали, что даже топовые модели вроде GPT-4 Multimodal не дотягивают до 60% точности в классификации уровня влияния действий в интерфейсе. Особенно тяжело им дается понимание нюансов, таких как возобновляемость действий или их влияние на других пользователей.
В итоге исследователи сделали несколько выводов: во-первых, для безопасной работы автономных ИИ-агентов нужны более сложные и нюансированные подходы к пониманию контекста; во-вторых, пользователям в будущем придется самостоятельно настраивать уровень "осторожности" своего ИИ — что можно делать без подтверждения, а что категорически нет.
Это исследование — важный шаг к тому, чтобы умные агенты в смартфонах не просто нажимали кнопки, а еще и понимали, что именно они делают и чем это может обернуться для человека.
Источник: Apple